What is a Vector Database and Why Does It Matter?
SQLFlash
7 min read


Image Source: pexels
A vector database keeps data as high-dimensional vectors. This makes it very useful for modern AI. Traditional databases use rows and columns to store data. Vector databases are better at handling things like pictures and words. They work well with unstructured data.
| Feature | Vector Database | Traditional Database |
|---|---|---|
| Data Representation | High-dimensional vectors | Rows and columns |
| Data Type | Unstructured data (images, text) | Structured and semi-structured data |
| Querying Method | Similarity search with embeddings | Exact keyword matches |
| AI Performance | Optimized for low-latency in AI | Less efficient for AI |
Many industries use these databases today. They help with things like semantic search and machine learning. This makes the market grow fast and apps get smarter.

Image Source: pexels
A vector database is made to hold and search high-dimensional vector data. It does not use rows and columns like regular databases. Instead, it stores data as arrays of numbers called vector embeddings. These embeddings show the meaning and features of things like text, images, audio, or video. People also call these systems vector stores or vector search engines.
A vector database does more than just keep data. It uses smart indexing and similarity search algorithms to spot patterns and links between data points. This lets you quickly find items that are alike, even if they are not exact matches. Many ai applications need this for things like recommendation, semantic search, and content discovery.
Tip: Vector databases use special indexing methods, like hashing or graph-based techniques, to make searches fast and accurate, even with millions of vectors.
Here is a quick look at the main parts of a vector database:
| Layer | Function |
|---|---|
| Storage Layer | Handles storing vector data and metadata, and takes care of encoding and compression. |
| Index Layer | Manages indexing algorithms, updates, and helps performance. |
| Query Layer | Deals with queries, picks how to run them, and handles results. |
| Service Layer | Manages client connections, routing, monitoring, logging, security, and multi-tenancy. |
These layers work together to allow real-time updates and fast retrieval. This is important for modern data processing needs.
Vector embeddings change complex data into arrays of numbers that computers can read. Each embedding is a high-dimensional vector that shows the meaning and context of the original data. For example, a sentence, a picture, or a sound clip can become a vector embedding.
Machine learning models make these embeddings by learning patterns from lots of data. Some popular embedding models are Word2Vec, GloVe, and BERT for text, CNNs for images, and CLAP for audio. These models help computers see how different pieces of data are related.
Vector embeddings help algorithms compare and group similar items.
They make raw data smaller and simpler, so data processing is faster.
Embeddings keep context, so they work well for things like semantic search and recommendation.
Common types of data that become vector embeddings include:
Text
Images
Videos
Audio
These embeddings power many ai applications, like chatbots and search engines.
Vector search means finding items in a vector database that are most like a given query. Instead of looking for exact matches, vector search uses math to measure how close two vectors are in high-dimensional space. This is called similarity search.
The process usually goes like this:
A user or system sends a query, like a sentence or an image.
The system turns the query into a vector embedding using an embedding model.
The vector database compares this embedding to all stored vectors using similarity metrics.
The database gives back the most similar items.
Some common similarity metrics include:
| Similarity Metric | What It Measures |
|---|---|
| Euclidean distance | Magnitude and direction |
| Cosine similarity | Direction only |
| Dot product similarity | Magnitude and direction |
Use Euclidean distance when the size of the vector matters.
Use cosine similarity when only the direction is important.
Use dot product when both size and direction matter.
Vector search often uses algorithms like Approximate Nearest Neighbor (ANN) to make retrieval faster. These algorithms can find similar items quickly, even in huge datasets. New advances, like mixing Word2Vec with Annoy Index or using new retrieval algorithms like MUVERA, have made searches even quicker and more accurate.
Vector search works better than regular keyword search, especially for big datasets and semantic queries. It can keep high accuracy and low latency, with some systems giving results in under 50 milliseconds. This makes vector databases a good choice for real-time apps that need fast and relevant results.
Note: Similarity searches in vector databases help users find related content, even if the words or images are not exactly the same.

Image Source: pexels
Many companies use vector databases for smart searching and recommendations. Healthcare teams turn molecules and genes into high-dimensional vectors. This helps them find similar drugs quickly. Finance groups use vector embeddings to spot patterns in trading and catch fraud. E-commerce sites use semantic vector search to match products with what users like. This makes recommendations better.
| Industry | Application Description |
|---|---|
| Healthcare | Vector databases turn molecules and genes into vectors for fast searches. |
| Finance | Quick similarity searches help with trading and finding fraud. |
| E-commerce | Products as vectors make recommendations more personal. |
Music apps like Spotify and SoundCloud use nearest neighbor search to suggest songs. Amazon and PayPal use vector databases to give product ideas and find fraud. Stravito and Vanguard made their search and support better by using Pinecone’s rag features.
Serverless vector databases are easy to grow, fast, and flexible. Companies pay only for what they use, so they save money. TiDB Serverless grows by itself and works with both scalar and vector data. It updates and finds data in real time. The schema-less design lets teams add new data sources fast.
| Advantage | Description |
|---|---|
| Scalability | Grows or shrinks easily when data changes. |
| Performance | Handles tough queries for advanced needs. |
| Flexibility | Schema-less design lets teams change data models quickly. |
There are some problems, like keeping data safe and managing systems. Teams need to make queries faster, keep data in sync, and watch costs. Security needs strong passwords, encryption, and checks.
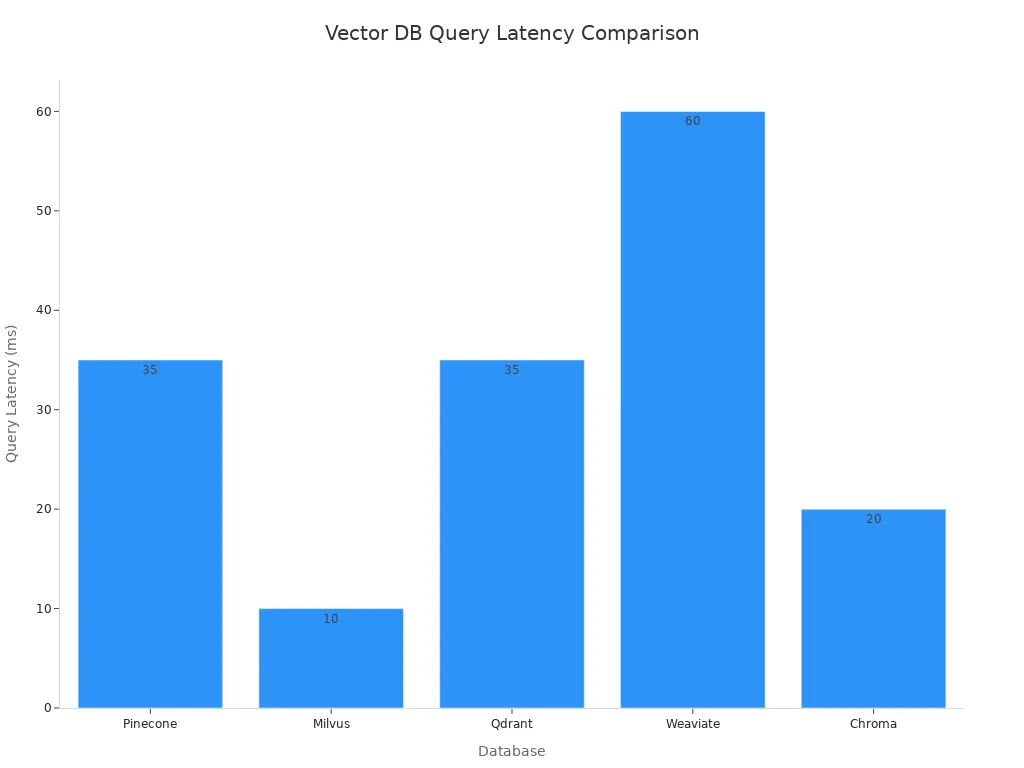
Many vector databases help ai apps work well. Pinecone is fast and good for real-time rag and similarity searches. It can handle billions of vectors with quick answers. Milvus uses many threads and sharding for big companies. Qdrant is great for real-time rag and nearest neighbor searches. Weaviate does semantic search and rag and is easy to use. Chroma works with CPUs and is good for medium-sized data. pgvector adds vector search to PostgreSQL for high-dimensional vectors. MongoDB with Vector Search makes old databases more flexible. FAISS and Annoy do nearest neighbor searches for big data sets. Elasticsearch uses k-NN plugins for similarity searches.
The market for vector databases is growing quickly. It is expected to grow by 22.1% each year. These tools help teams do rag, recommendations, and searches with fast results and real-time updates.
Vector databases are making AI and data use different. They help big companies like Amazon and Shopify. These companies can give better searches and suggestions. Some new trends make vector databases more popular. Real-time data lets them do hard searches quickly. Cloud growth helps them grow or shrink as needed.
| Trend Description | Impact of Vector Databases |
|---|---|
| Real-time data | Does hard searches quickly |
| Cloud growth | Makes it easy to grow |
Want to know more? Look at resources about top vector database solutions for more details.
SQLFlash is your AI-powered SQL Optimization Partner.
Based on AI models, we accurately identify SQL performance bottlenecks and optimize query performance, freeing you from the cumbersome SQL tuning process so you can fully focus on developing and implementing business logic.
Join us and experience the power of SQLFlash today!.