How to Connect MCP to PostgreSQL/MySQL with Claude Skills
Rebooter.S
9 min read
If your team is tired of one-off scripts, brittle connectors, and risky ad‑hoc SQL, there’s a cleaner path. MCP gives you a standard way to expose safe database tools, and Skills encode repeatable procedures. Pair them and you get faster diagnostics and controlled access without sacrificing governance. This guide focuses on Model Context Protocol database integration patterns that help engineers work quickly while keeping production safe.
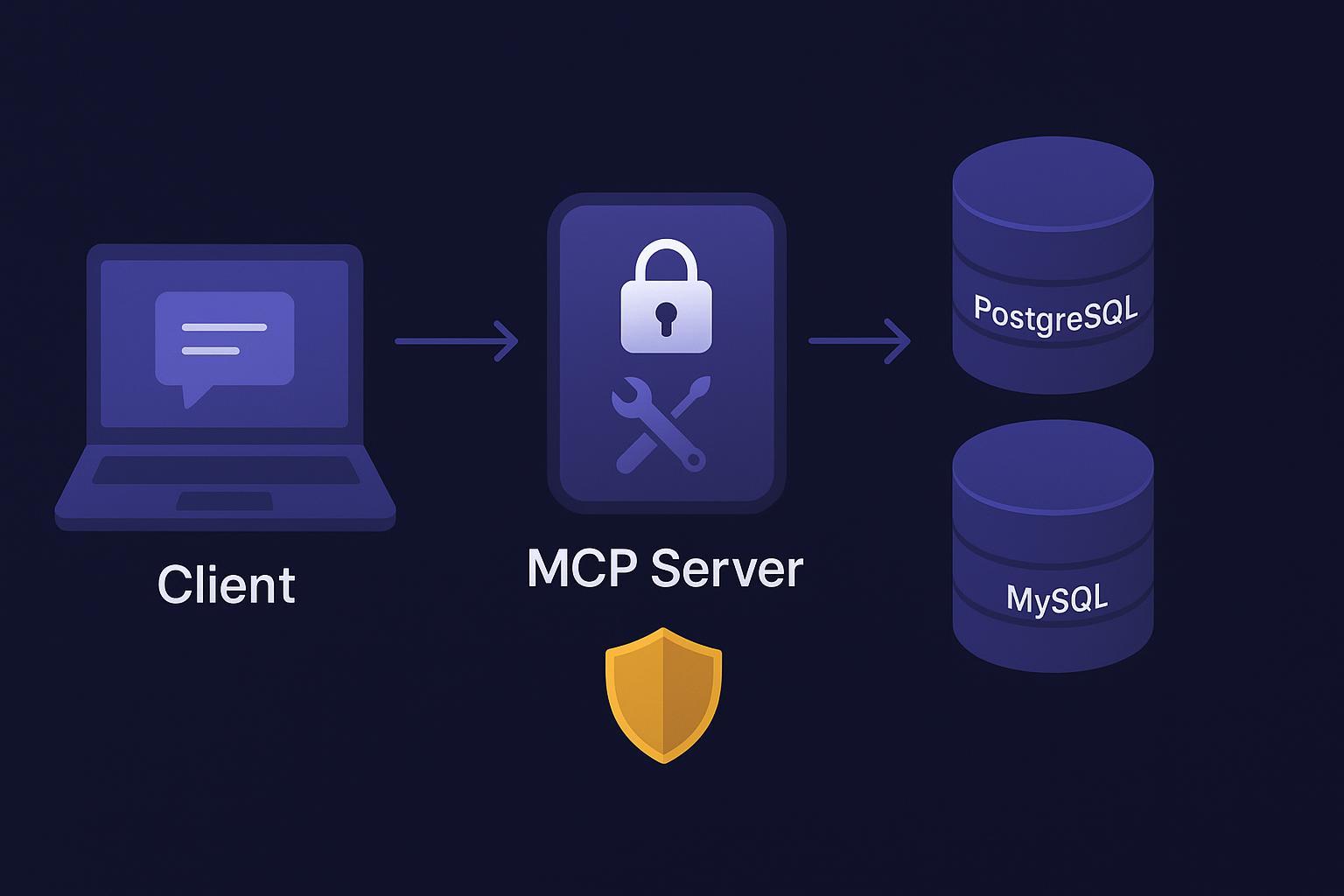
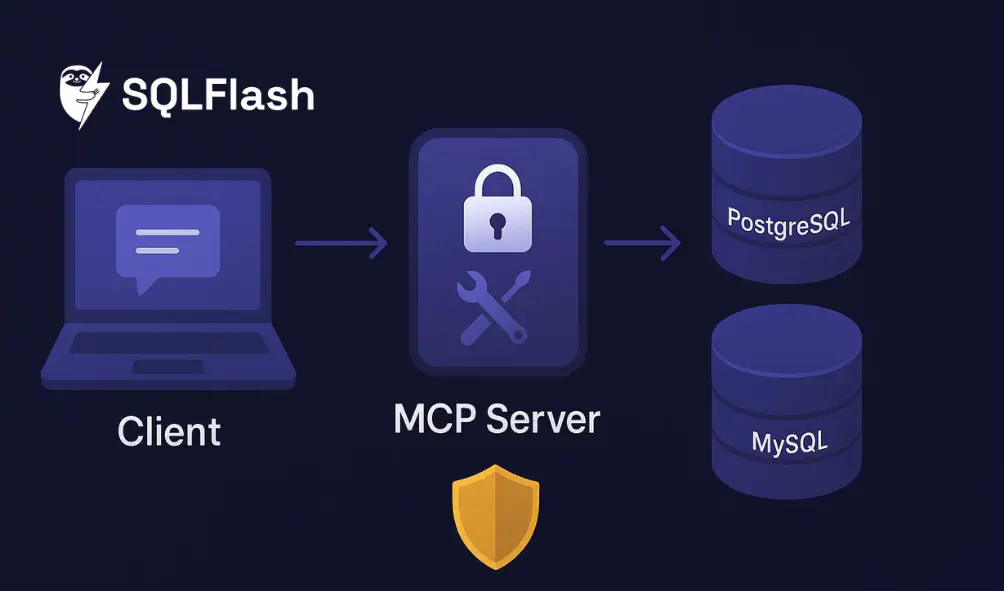
MCP (Model Context Protocol) is an open standard that lets AI hosts connect to external systems via server‑defined tools with JSON‑RPC schemas. It’s the connectivity layer. Skills are portable, file‑based packages that teach the host “how” to do a task—procedures, checks, and decision points. In practice, MCP provides the handles into PostgreSQL/MySQL, while Skills orchestrate the sequence—run EXPLAIN, review stats, propose next steps.
For background, consult the MCP tools specification and the engineering post on code execution with MCP. To understand Skills, start with the Agent Skills overview.
A practical setup has three pieces: the host/client that mediates authorization and tool calls, a small MCP server that exposes a safe subset of database operations as tools, and the database accessed through a read‑only role. To keep production safe, design with conservative defaults: least privilege, schema allowlists, parameter binding, single‑statement queries only, tight timeouts (5–10 seconds), row and payload caps, and structured audit logging with correlation IDs and PII redaction. Use stdio transport for local development and HTTPS with OAuth 2.1 plus PKCE for remote servers.
MCP’s transport documentation covers stdio vs HTTP and session management; see MCP transports. The spec also outlines security guidance—review Security best practices.
Local (stdio) quickstart using Claude Code CLI:
| |
Remote (HTTP) connector example via project config:
| |
Use HTTPS and OAuth for production. The spec explains scope‑based access; review Authorization best practices.
Expose four tools: run_parameterized_select for bound‑variable SELECTs with row/time limits; run_explain for EXPLAIN on parameterized queries, keeping ANALYZE under a separate elevated scope; get_db_stats for limited diagnostics (pg_stat_statements summaries or MySQL SHOW STATUS); and list_schema for schema metadata to inform audits.
Example TypeScript scaffold (Node + pg/mysql2):
| |
PostgreSQL EXPLAIN formats are documented in the official manual. MySQL’s EXPLAIN output formats are covered in MySQL’s EXPLAIN documentation.
Skills package repeatable workflows. Keep them small and explicit. Here’s a minimal skeleton:
| |
In Claude Code, you can restrict which tools a skill can call via configuration; see Skills best practices.
Provide a parameterized SELECT and its params. Run EXPLAIN without ANALYZE. Check for sequential scans, problematic join orders, and missing indexes. In PostgreSQL, compare estimates to actuals only in a safe sandbox with ANALYZE; otherwise rely on estimates and stats. The EXPLAIN command is described in the PostgreSQL EXPLAIN manual. In MySQL, favor EXPLAIN FORMAT=JSON for richer detail; see MySQL’s EXPLAIN output reference.
Example prompt to the skill:
| |
Use list_schema to enumerate current indexes. Review WHERE predicates and JOIN keys from typical queries. Propose a composite index if selectivity warrants, then validate with run_explain on the representative query.
Compare schema snapshots via list_schema and flag operations that require full table rebuilds. Estimate impact via small sample row counts and index rebuild heuristics. Produce a rollout plan with backout steps and monitoring hooks—watch p95 latency and deadlocks. Keep ANALYZE off on production during validation. For deeper diagnostics, PostgreSQL environments often use pg_stat_statements; see pg_stat_statements documentation.
Keep least privilege across the stack. Separate scopes for EXPLAIN vs ANALYZE and default to read‑only. Minimize data by using parameterized templates, capping rows, redacting PII in logs, and avoiding large result sets in chat context. Apply RBAC so only specific roles can install or invoke servers and skills; require approvals for elevated scopes. Audit with structured logs and correlation IDs, rotate tokens, and review access regularly. Pin versions, verify signatures when available, and vet third‑party servers and skills.
The spec outlines security guidance—review Security best practices.
Authentication failures typically come from mismatched OAuth client registrations, redirect URIs, or scope alignment. Timeouts indicate heavy queries; prefer EXPLAIN over ANALYZE and block long‑running tool calls. If desktop or CLI connectors misbehave, restart, check OS permissions, and verify extension settings. Manage context pressure by keeping intermediate results out of conversation history and summarizing large payloads.
Operational limits that work well include 5–10 seconds per tool call, caps of 1–10k rows, strict payload truncation with a visible “truncated” flag, and single‑statement queries only. Block DDL and DML except in tightly controlled sandboxes. For client configuration and debugging tips, consult Claude Code’s MCP documentation.
Build the server locally, wire it to Claude, and try the three Skills. Start small, keep guardrails tight, and expand scopes only when the procedure is proven. What workflow do you want to automate next—index maintenance windows or query‑store‑driven regressions?
SQLFlash is your AI-powered SQL Optimization Partner.
Based on AI models, we accurately identify SQL performance bottlenecks and optimize query performance, freeing you from the cumbersome SQL tuning process so you can fully focus on developing and implementing business logic.
Join us and experience the power of SQLFlash today!.