SQL Rewriting vs Indexing: How AI-Powered Structural Optimization Achieves 20x Scalability Gains
Rebooter.S
20 min read

Through comprehensive MySQL query performance experiments, this study systematically evaluates the effectiveness of SQL rewriting versus index optimization across different data scales and combination scenarios. Using a typical slow SQL query as our benchmark, we leveraged SQLFlash to generate optimized query rewrites and conducted comparative testing with various indexing strategies.
The results demonstrate that structural SQL optimization provides both greater versatility and more sustainable performance during data growth. SQLFlash proves exceptionally practical in generating actionable rewriting recommendations, offering clear and efficient optimization pathways for real-world engineering scenarios.
To validate the effectiveness of SQLFlash’s query rewriting solutions across different data scales, we designed the following experimental framework based on simulated business scenarios.
We generated simulated transaction business data (customers, transaction details, service records, risk monitoring) using Python scripts. Data insertion volume was controlled by the NUM_RECORDS variable, scaling the master table from 11,000 to 500,000 records.
Execute the following SQL to create the required database tables:
| |
Run the Python script (provided at the end) to generate simulated test data.
The script creates a realistic financial transaction environment simulating multi-table join queries. Key data characteristics include:
This analysis focuses on a slow-performing SQL query that retrieves transaction details flagged by the risk monitoring system as money laundering, fraud, or abnormal fund activity between September 24-26, 2024. The query was identified as problematic when the main table contained only 11,000 records.
With an execution time of 1 minute and 1.09 seconds, this query became our primary optimization target:
| |
To systematically evaluate the actual impact of different optimization strategies on query performance, we designed and executed a series of experiments based on real business scenarios. The tests covered performance changes at each stage of SQL rewriting, as well as the synergistic effects and sustainability of combining SQL rewriting with index optimization across different data scales. The following charts and analyses reveal the relationship between structural optimization and index optimization, along with their respective boundaries.
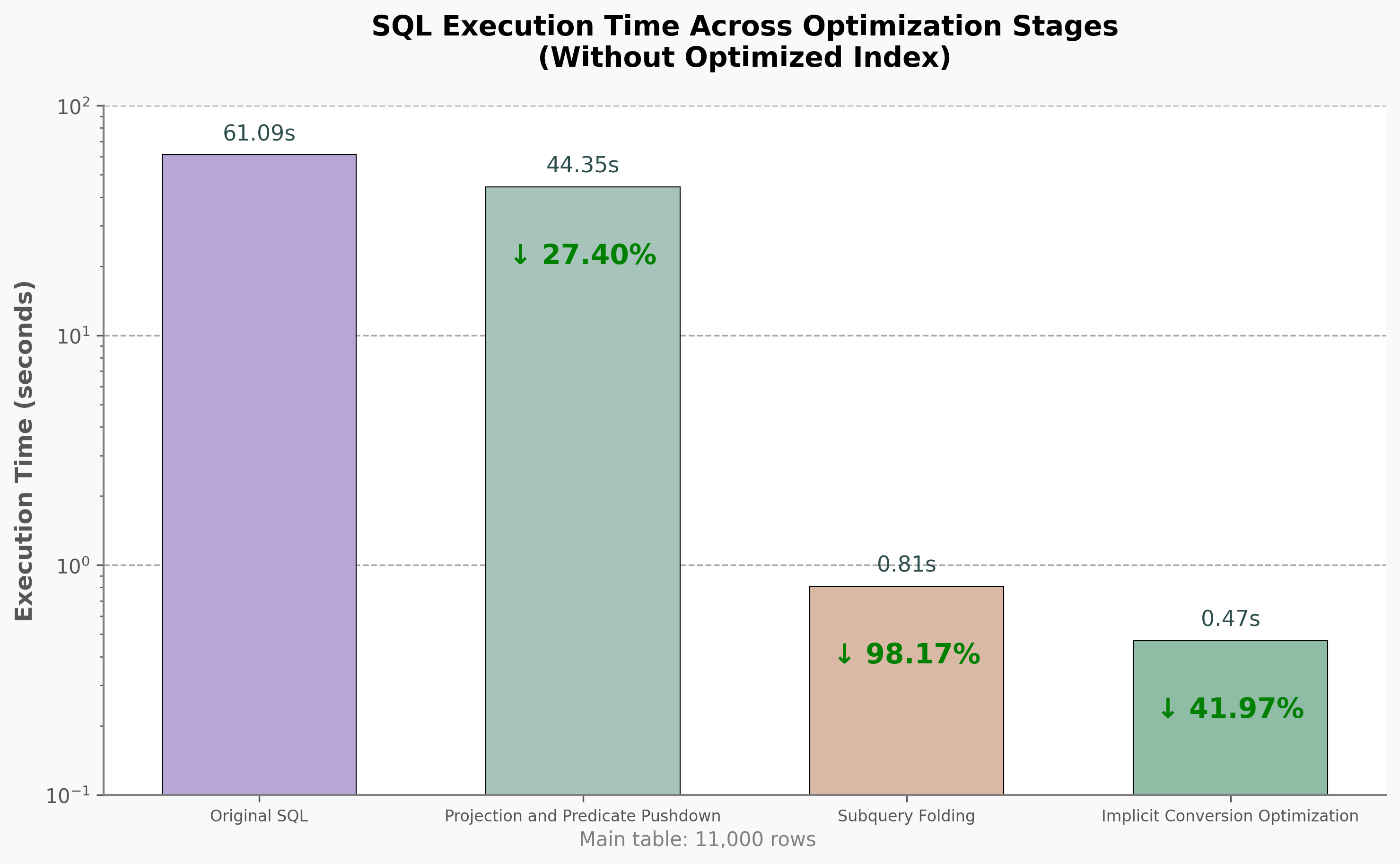
The chart shows the execution time evolution during SQL rewriting without added indexes. The optimization process can be divided into three key phases:
Phase 1: Projection Pushdown and Predicate Pushdown
By moving column selection and filtering conditions closer to the data source, we reduced unnecessary data reading and transfer. Execution time dropped from 61.09s to 44.35s (27% improvement).
✨ Primary benefit: Reduced data scanning and transfer bottlenecks
Phase 2: Subquery Folding
Rewriting nested subqueries into equivalent JOIN statements simplified execution logic. Time plummeted to 0.81s (98%+ improvement).
✨ Primary benefit: Eliminated structural complexity and computational redundancy
Phase 3: Implicit Conversion Optimization
Removing function-wrapped expressions and type mismatches restored index utilization efficiency. Final time: 0.47s.
✨ Primary benefit: Fixed index inefficiency issues
Collectively, these optimizations compressed query time from minutes to milliseconds, demonstrating the core value of structural query optimization.
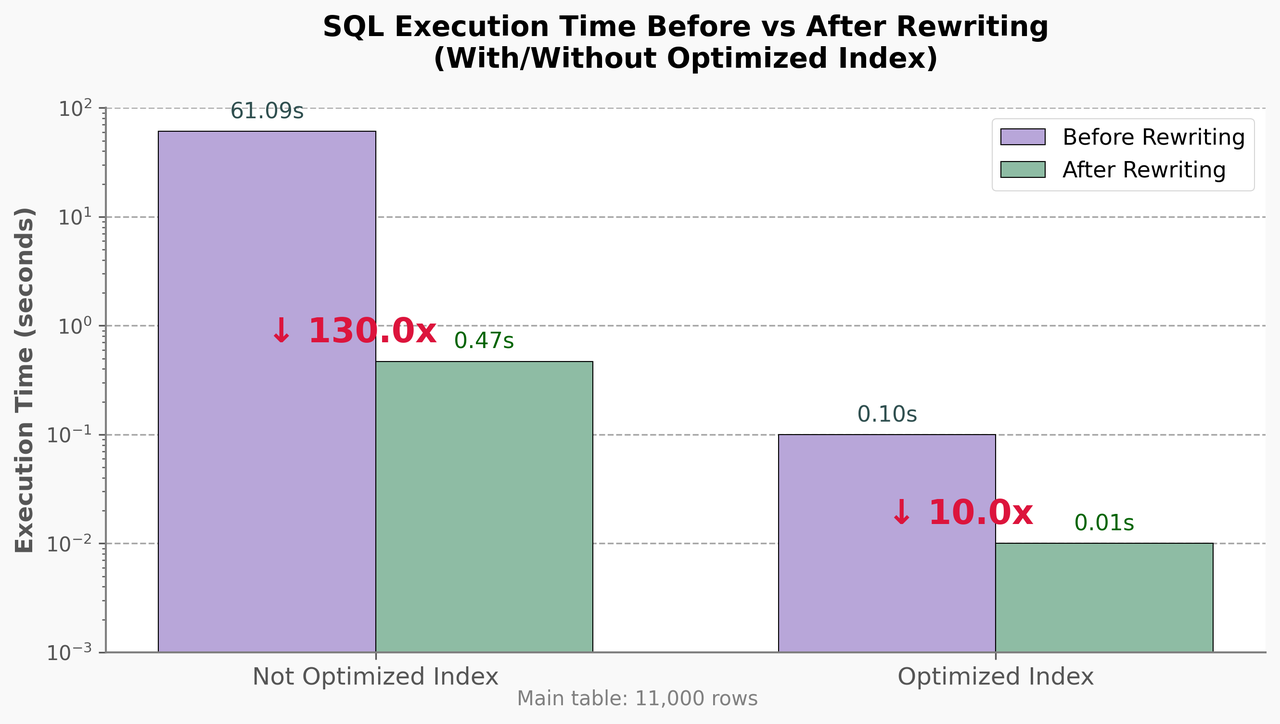
Testing four scenarios with 11,000 rows:
| Scenario | SQL Version | Index Strategy | Performance |
|---|---|---|---|
| 1 | Original | No optimization | 61s |
| 2 | Rewritten | No optimization | 0.47s (130x faster) |
| 3 | Original | Optimized indexes | 0.1s |
| 4 | Rewritten | Optimized indexes | 0.01s |
Key findings:
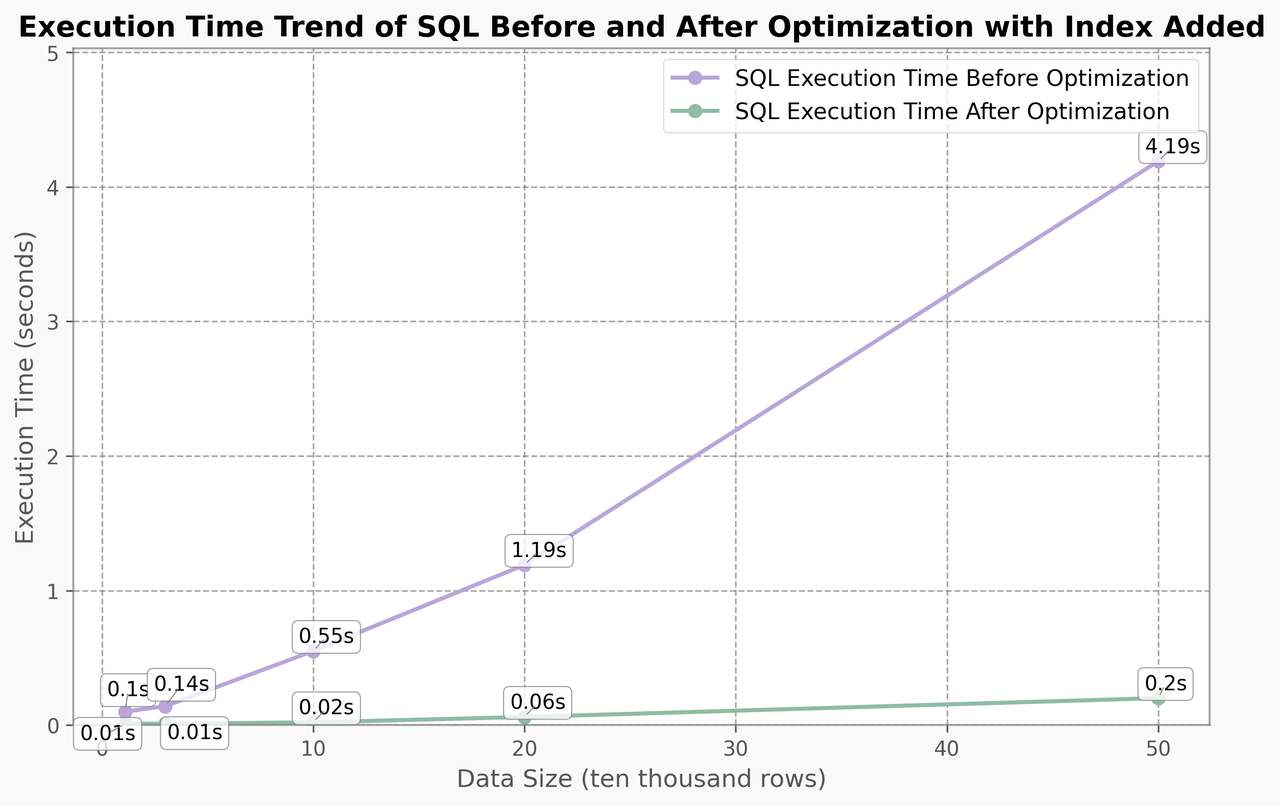
Performance comparison during data growth (with consistent indexing):
| Data Volume | Original SQL | Rewritten SQL |
|---|---|---|
| 30K rows | 0.14s (+40%) | 0.01s |
| 100K rows | 0.55s | 0.02s |
| 500K rows | 4.19s | <0.2s (20x advantage) |
Key takeaways:
For business systems with growth expectations, relying solely on indexing cannot support long-term performance needs. Structural SQL optimization should be prioritized in system design, often taking precedence over index optimization in strategic planning.
Traditional SQL optimization relies heavily on experienced engineers manually analyzing execution plans, adjusting query logic, and designing index structures - a time-consuming process with inconsistent results.
With SQLFlash’s AI-powered optimization, this becomes effortless. Simply provide:
SQLFlash automatically analyzes and generates optimization recommendations. Implement the key suggestions relevant to your business to significantly improve query performance.
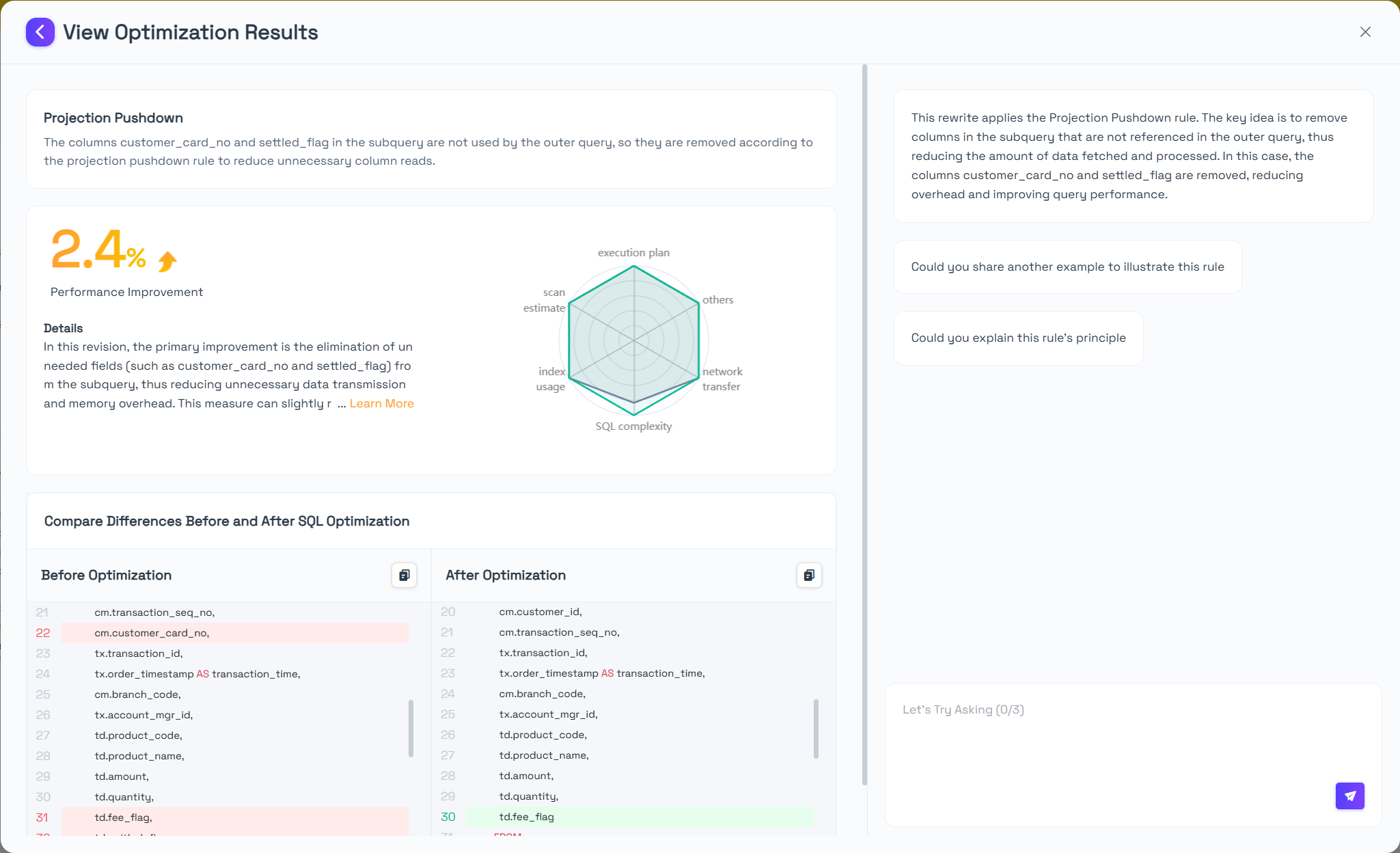
In this revision, the primary improvement is the elimination of unneeded fields (such as customer_card_no and settled_flag) from the subquery, thus reducing unnecessary data transmission and memory overhead. This measure can slightly reduce the row size and CPU load in the subquery phase when dealing with large data volumes, bringing a certain positive impact on overall performance. Moreover, removing unused columns helps the query logic remain more focused and concise, enhancing maintainability and readability. Although the main structure of the query remains largely unchanged, these minor adjustments can still provide some resource optimization benefits in scenarios with large data sets.
Projection pushdown is a relational algebra optimization that eliminates unnecessary columns early in query execution by pushing column selection down to the base tables, subqueries, views or join inputs. This significantly reduces resource consumption and improves efficiency.
Key benefits:
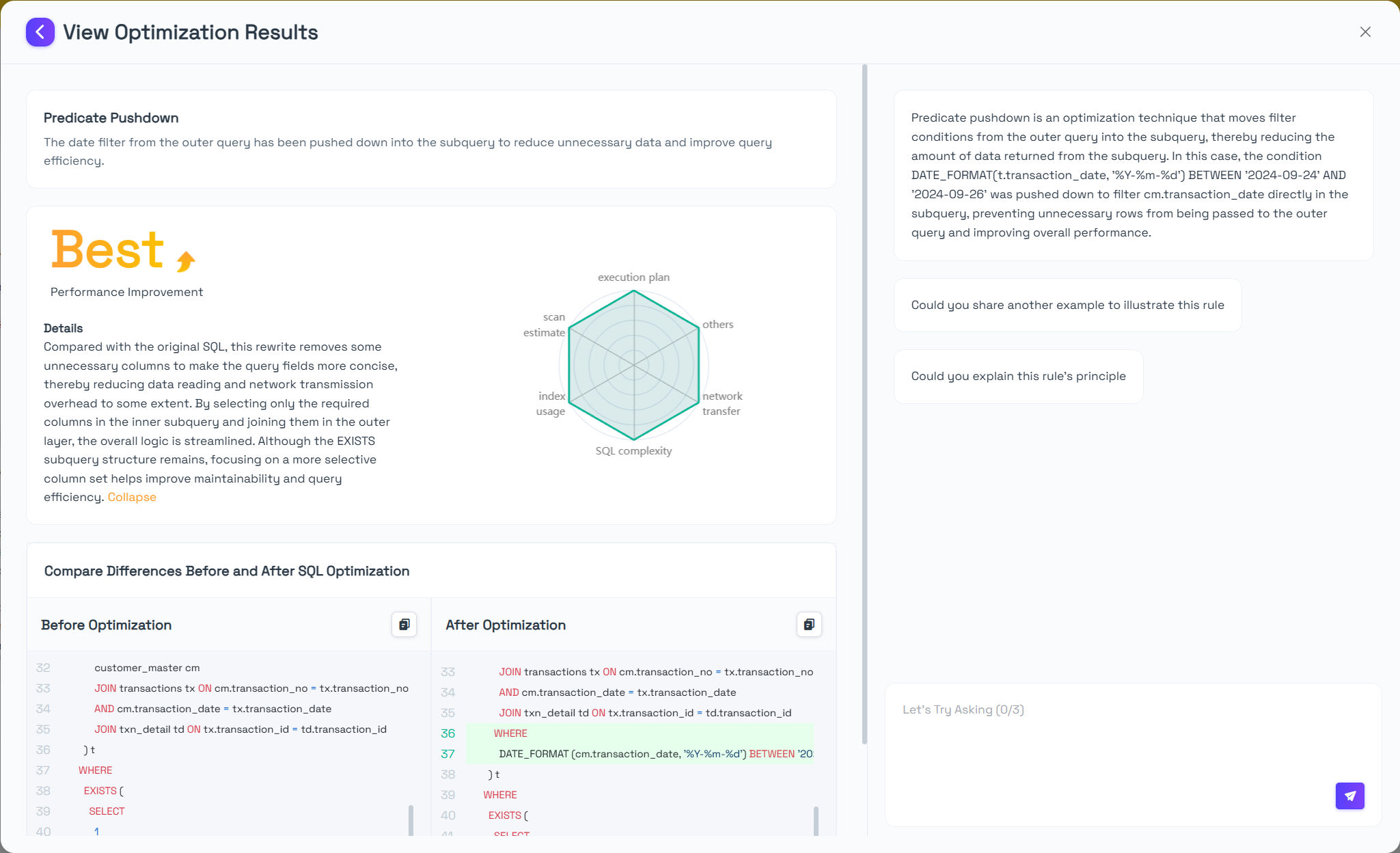
Compared with the original SQL, this rewrite removes some unnecessary columns to make the query fields more concise, thereby reducing data reading and network transmission overhead to some extent. By selecting only the required columns in the inner subquery and joining them in the outer layer, the overall logic is streamlined. Although the EXISTS subquery structure remains, focusing on a more selective column set helps improve maintainability and query efficiency.
Pushes filtering conditions as close to the data source as possible to reduce intermediate result sizes and CPU/IO overhead [2].
Key benefits:
After applying both pushdown techniques:
| |
Performance: 44.35s (27.41% faster than original 61.09s)
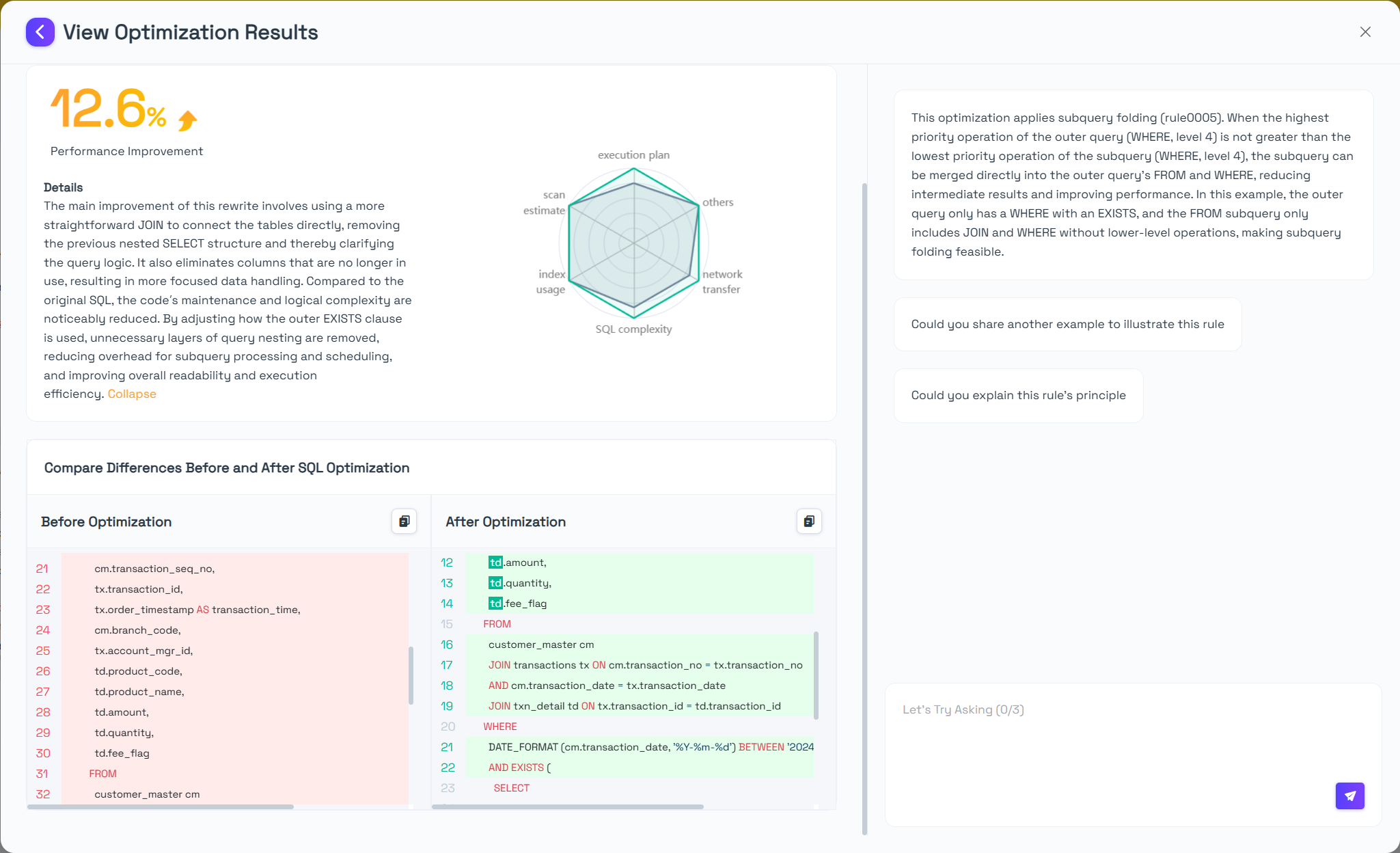
The main improvement of this rewrite involves using a more straightforward JOIN to connect the tables directly, removing the previous nested SELECT structure and thereby clarifying the query logic. It also eliminates columns that are no longer in use, resulting in more focused data handling. Compared to the original SQL, the codeʼs maintenance and logical complexity are noticeably reduced. By adjusting how the outer EXISTS clause is used, unnecessary layers of query nesting are removed, reducing overhead for subquery processing and scheduling, and improving overall readability and execution efficiency.
Flattens nested subqueries into main query structure for better optimization [3].
Key benefits:
Optimized query:
| |
Performance: 0.81s (75x faster)
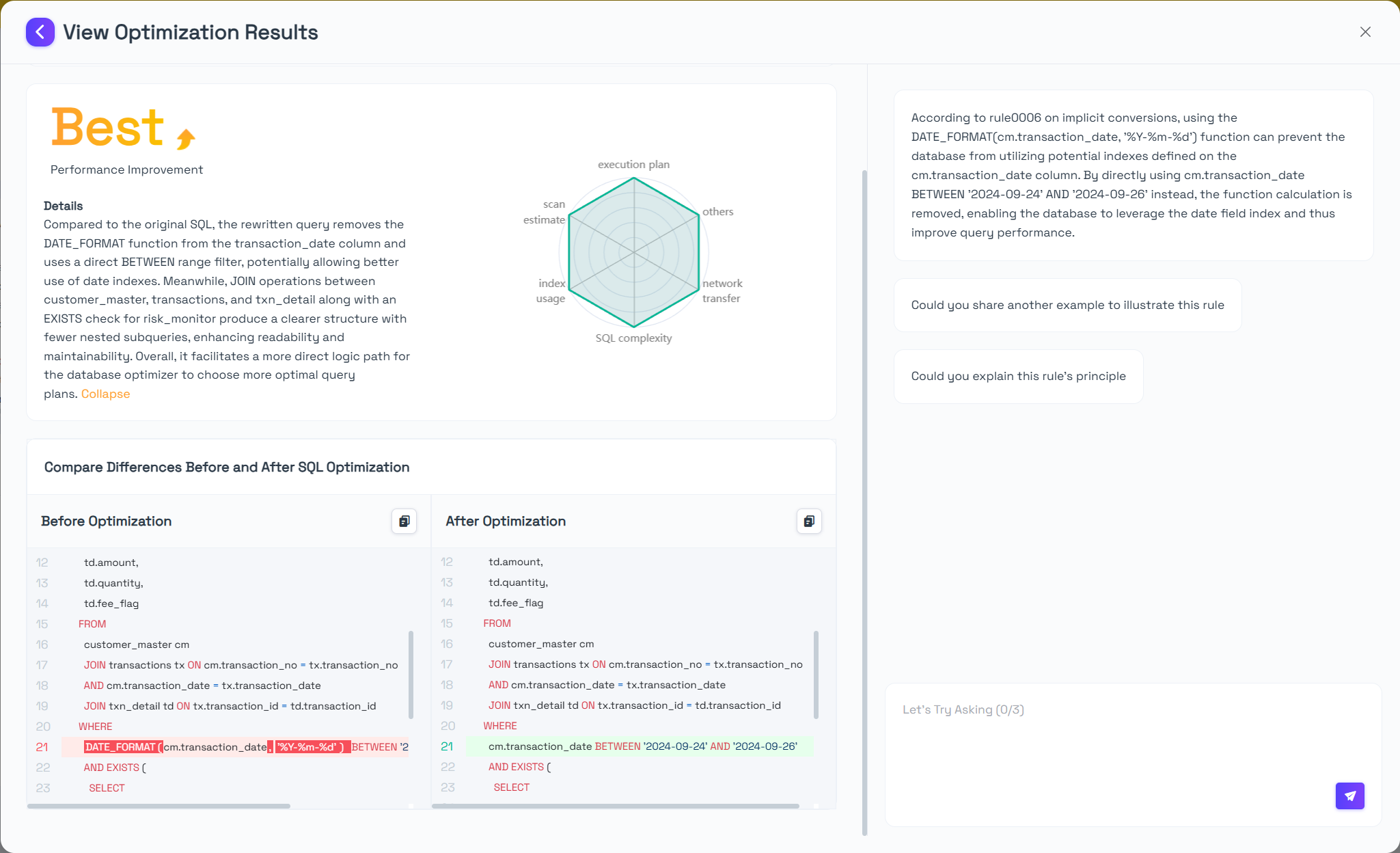
Compared to the original SQL, the rewritten query removes the DATE_FORMAT function from the transaction_date column and uses a direct BETWEEN range filter, potentially allowing better use of date indexes. Meanwhile, JOIN operations between customer_master, transactions, and txn_detail along with an EXISTS check for risk_monitor produce a clearer structure with fewer nested subqueries, enhancing readability and maintainability. Overall, it facilitates a more direct logic path for the database optimizer to choose more optimal query plans.
Avoids data type mismatches that prevent index usage and increase CPU load [4].
Key benefits:
Final optimized query:
| |
Performance: 0.47s (130x faster)
| |
Based on the rewritten execution plan and SQLFlash’s index optimization recommendations, we selected these three indexes for implementation: idx_cm_date_no, idx_tx_no_date, and idx_rm_no_date. Here’s the technical analysis:
idx_cm_date_no(transaction_date, transaction_no):
transaction_date in the WHERE clausetransaction_no matching in JOIN operationsidx_tx_no_date(transaction_no, transaction_date):
idx_rm_no_date(transaction_no, transaction_date):
After implementing these indexes, the execution plan for the rewritten SQL shows:
| |
The optimized execution plan after index implementation demonstrates significant performance improvements, with these key changes:
customer_master table:
transactions table:
txn_detail table:
risk_monitor subquery:
Overall impact: The indexed execution plan optimizes table access patterns, eliminates unnecessary data processing, and delivers substantial query performance gains - particularly for JOIN operations and subquery execution.
[1] J. Wang, “Lecture #14 Query Planning & Optimization,” Carnegie Mellon University, Fall 2022. [Online]. Available: https://15445.courses.cs.cmu.edu/fall2022/notes/14-optimization.pdf (Accessed: May 21, 2025).
[2] Microsoft Research, “MagicPush: Deciding Predicate Pushdown using Search-Verification,” Microsoft Research, 2023. [Online]. Available: https://www.microsoft.com/en-us/research/uploads/prod/2023/05/predicate_pushdown_final.pdf (Accessed: May 21, 2025).
[3] C. A. Galindo-Legaria and M. M. Joshi, “Orthogonal Optimization of Subqueries and Aggregation,” in Proc. 31st Int. Conf. on Very Large Data Bases (VLDB), 2005, pp. 571-582.
[4] Wayfair Engineering, “Eliminate Implicit Conversions,” Wayfair Tech Blog, [Online]. Available: https://www.aboutwayfair.com/eliminate-implicit-conversions (Accessed: May 21, 2025).
| |
SQLFlash is your AI-powered SQL Optimization Partner.
Based on AI models, we accurately identify SQL performance bottlenecks and optimize query performance, freeing you from the cumbersome SQL tuning process so you can fully focus on developing and implementing business logic.
Join us and experience the power of SQLFlash today!.