AI-Driven SQL Dataset Optimization 202506
Rebooter.S
10 min read

When we conduct AI research in the field of SQL, we find that the improvement of application capabilities in the SQL field largely depends on high-quality datasets. We need to synthesize data based on this to generate training sets and evaluation sets for specific problems. To help more developers quickly access resources, we have sorted out a list of publicly available Text2SQL datasets in recent years and share them with you here.
We have organized the papers and dataset addresses of the datasets in chronological order, including representative Text2SQL datasets in recent years. Among them, representatives of the evaluation set: Spider, BIRD-SQL, we have also associated the leaderboard in our list.
Next, I will focus on introducing the latest dataset in 2025, and will continue to collect and bring the latest information to everyone.
Prev: AI-Driven SQL Dataset Optimization 202505
To characterize the scientific and computational complexity of BiomedSQL, auther annotated all 68,000 question–query pairs with SQL operation types and biomedical reasoning categories. Simpler operations—such as Select, Order-By, and Calculate—require relatively shallow syntactic parsing, which LLMs tend to perform well on. In contrast, operations such as Multi-Filter, Threshold, Join, and Similarity Search present greater difficulty, as they demand multi-step logical composition, implicit schema linking, or pattern-based retrieval.
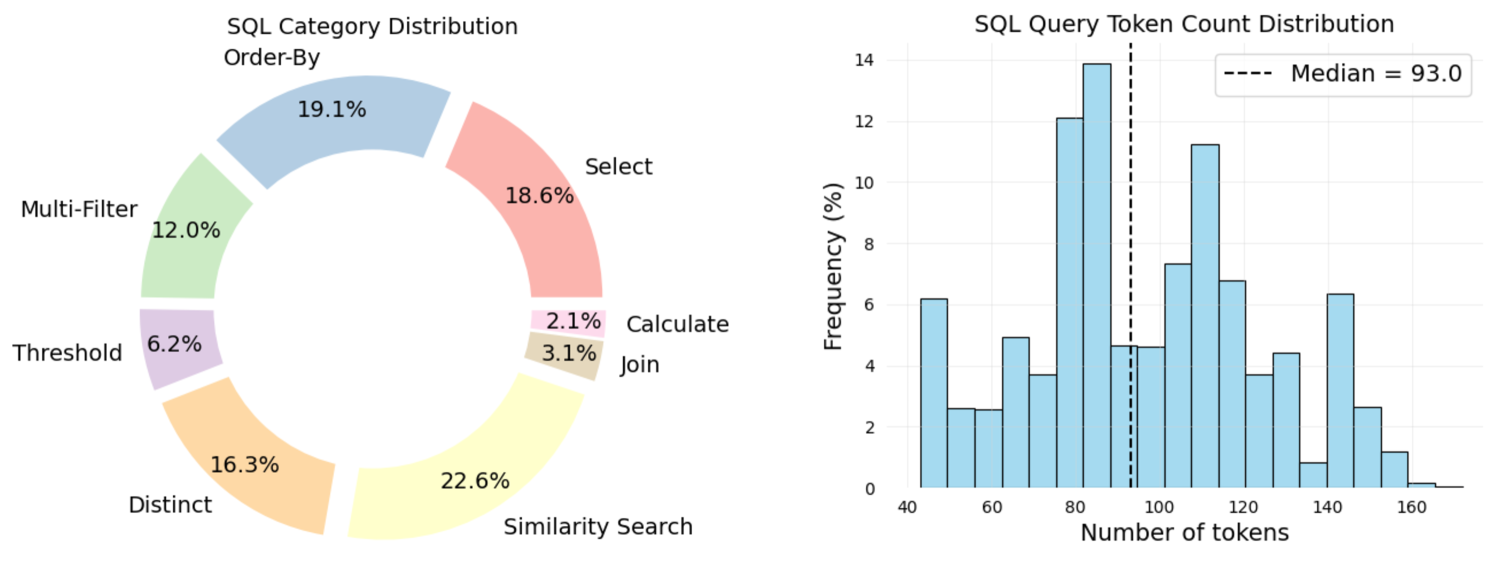
BiomedSQL is the first benchmark evaluating scientific reasoning in text-to-SQL systems for biomedical research, featuring 68,000 question/SQL/answer triples executable on a real-world BigQuery database integrating gene-disease associations, drug targets, and omics data.
Scientific reasoning categories. To probe scientific reasoning, we classified BiomedSQL queries into three reasoning categories reflecting cognitive processes typical of biomedical experts:
Operationalizing implicit scientific conventions: Queries often invoke domain-specific concepts (e.g., “significantly associated SNPs”) that imply non-obvious statistical thresholds, such as p<5×10−8 for GWAS hits or directionality based on beta coefficients. These conventions are rarely explicit in schemas and must be inferred by models.
Incorporating missing contextual knowledge: Experts frequently incorporate auxiliary data (e.g., drug approval status or clinical trial phase) even when not directly mentioned in a question. For instance, determining whether a drug is “approved” for a condition requires disambiguating indication-specific trial phase information—beyond any binary “approved” flag.
Executing complex multi-hop reasoning workflows: Many questions in BiomedSQL require chaining relational operations across multiple tables. For example, “Which tissues are genes associated with Parkinson’s disease most significantly expressed in?” requires a four-step inference over gene–disease, gene–expression, tissue annotations, and statistical ranking. LLMs often struggle to translate such multi-hop logic into valid, executable SQL.
This is the first large-scale text-to-SQL benchmark specifically designed to evaluate scientific reasoning in SQL generation for the biomedical field. Experimental results in the paper demonstrate that BiomedSQL poses significant challenges to current state-of-the-art LLMs, with execution accuracy and answer quality still lagging far behind the performance of domain experts. By focusing on implicit domain conventions, multi-step reasoning, and structured biomedical data, BiomedSQL highlights critical limitations of existing systems and provides a rigorous testing platform for future research.
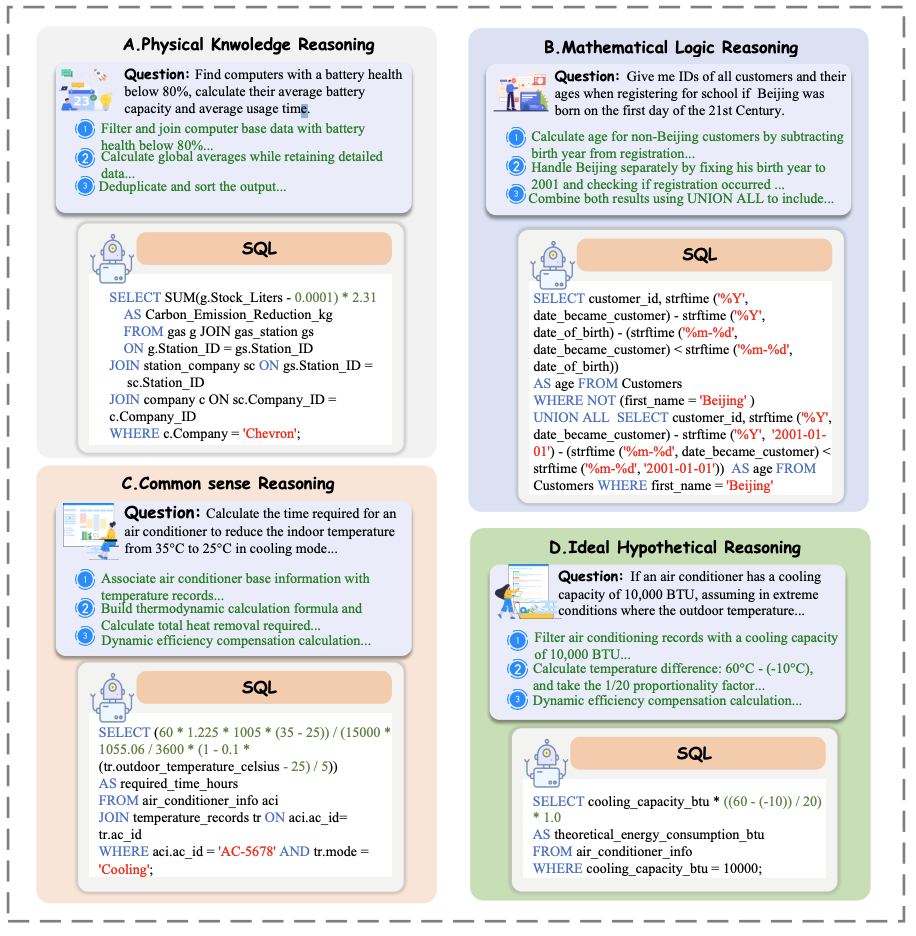
LogicCat include four types of reasoning:
physical knowledge reasoning:Focuses on solving physics problems using formulas and unit-aware calculations. Tests the ability to apply physical principles in multi-step reasoning.
mathematical logic reasoning:Involves arithmetic, logical, and analytical thinking to solve math problems. Features complex computations and data manipulation.
common sense reasoning:Requires real-world knowledge to infer implicit details and generate logical SQL queries. Helps in zero-shot learning and improving model interpretability.
ideal hypothetical reasoning:Tests counterfactual and imaginative thinking in unseen scenarios. Challenges models with complex conditional relationships.
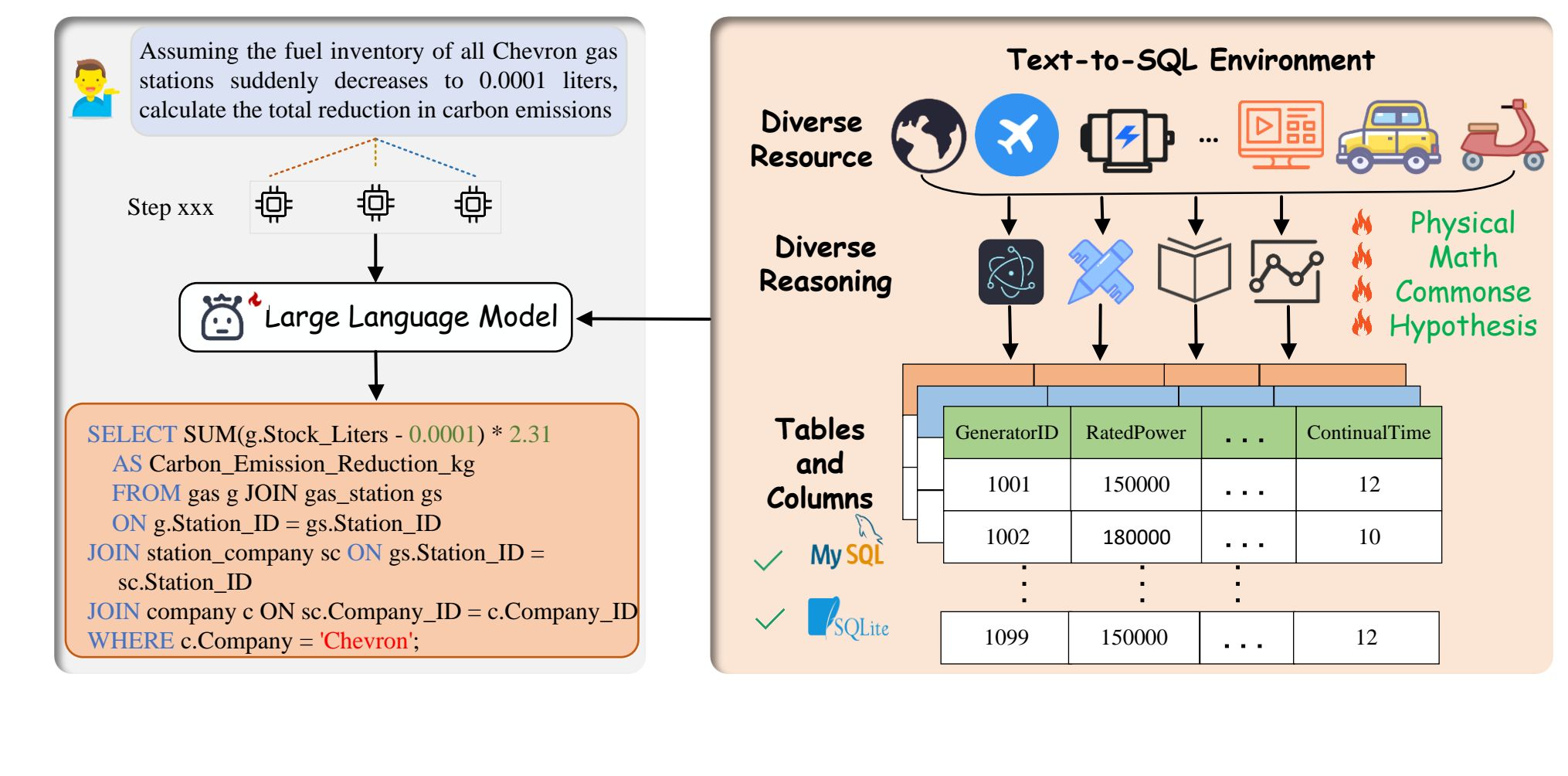
This paper addresses the limitations of existing text-to-SQL datasets in terms of complex logical reasoning and domain knowledge coverage. Specifically, the authors point out that while current datasets (such as Spider and BIRD) provide challenges in SQL parsing and execution, they fall short in evaluating deep logical reasoning and computational capabilities. These datasets often lack coverage of domain-specific knowledge and complex mathematical reasoning, making them inadequate for assessing models’ advanced reasoning and precise numerical computation abilities in real-world applications.
To address this gap, the paper introduces a new dataset—LogicCat—designed to advance text-to-SQL models in logical reasoning and domain knowledge integration. By incorporating complex reasoning tasks spanning physics, mathematics, commonsense reasoning, and hypothetical reasoning, LogicCat aims to push the boundaries of model performance in structured query generation under demanding cognitive and domain-specific constraints.
| Dataset | Link | Desc |
|---|---|---|
| BiomedSQL | [Paper][Dataset] | BiomedSQL is a text-to-SQL benchmark designed to evaluate Large Language Models (LLMs) on scientific tabular reasoning tasks. It consists of curated question-SQL query-answer triples covering a variety of biomedical and SQL reasoning types. The benchmark challenges models to apply implicit scientific criteria rather than simply translating syntax. |
| LogicCat | [Paper] [Dataset] | LogicCat is a challenging Text-to-SQL dataset designed to test complex reasoning, including physical, arithmetic, commonsense, and hypothetical reasoning. It contains 4,038 English questions paired with SQL queries and 12,114 step-by-step reasoning annotations across 45 diverse databases. Experiments show state-of-the-art models struggle, achieving only 14.96% accuracy, but performance improves to 33.96% with chain-of-thought annotations, highlighting its potential for advancing reasoning-driven SQL generation. |
| TINYSQL | [Paper][Dateset] | 2025/03, TinySQL is a structured text-to-SQL dataset designed to support interpretability research by bridging toy examples and real-world tasks with controllable complexity. |
| NL2SQL-Bugs | [Paper][Dateset] | 2025/03, NL2SQL-BUGs is the benchmark dedicated to detecting and categorizing semantic errors in Natural Language to SQL (NL2SQL) translation. While state-of-the-art NL2SQL models have made significant progress in translating natural language queries to SQL, they still frequently generate semantically incorrect queries that may execute successfully but produce incorrect results. This benchmark aims to support research in semantic error detection, which is a prerequisite for any subsequent error correction. |
| OmniSQL | [Paper][Dateset] | 2025/03, As of March 2025, SynSQL-2.5M is the largest and most diverse synthetic text-to-SQL dataset to date. It represents a significant milestone in the text-to-SQL community. We encourage researchers, practitioners, and data enthusiasts to explore and build models using this dataset. If you find it useful, please consider giving us a star or citing our work. Your feedback is our greatest motivation to continue advancing. |
| Dataset | Link | Desc |
|---|---|---|
| WikiSQL | [Paper][Dateset] | 2017/09, Salesforce proposes a large Text-to-SQL dataset WikiSQL, the data comes from Wikipedia, which belongs to a single domain, contains 80,654 natural language questions, and 77,840 SQL statements. The form of SQL statements is relatively simple, and does not include sorting, grouping, and subqueries and other complex operations. |
| Spider 1.0 | [Paper][Leaderboard] | 2018/09, Yale University proposes the Text-to-SQL dataset Spider with multiple databases, multiple tables, and single-round query. It is also recognized as the most difficult large-scale cross-domain evaluation list in the industry. It contains 10,181 natural language questions and 5,693 SQL statements |
| SParC | [Paper][Leaderboard] | 2019/06, Yale University proposes a large dataset SParC for complex, cross-domain, and context-dependent(multi-turn) semantic parsing and text-to-SQL task, which consists of 4,298 coherent question sequences (12k+ unique individual questions annotated with SQL queries annotated by 14 Yale students), obtained from user interactions with 200 complex databases over 138 domains. |
| CSpider | [Paper][Leaderboard] | 2019/09, Westlake University propposes a large Chinese dataset CSpider for complex and cross-domain semantic parsing and text-to-SQL task, translated from Spider by 2 NLP researchers and 1 computer science student, which consists of 10,181 questions and 5,693 unique complex SQL queries on 200 databases with multiple tables covering 138 different domains. |
| CoSQL | [Paper][Leaderboard] | 2019/09, Yale University and Salesforce Research propose a cross-domain database CoSQL, which consists of 30k+ turns plus 10k+ annotated SQL queries, obtained from a Wizard-of-Oz (WOZ) collection of 3k dialogues querying 200 complex DBs spanning 138 domains. |
| KaggleDBQA | [Paper][dataset] | 2021/06, KaggleDBQA is a challenging cross-domain and complex evaluation dataset of real Web databases, with domain-specific data types, original formatting, and unrestricted questions. |
| Spider-Syn | [Paper][Dateset] | 2021/06, Spider-Syn is a benchmark dataset designed to evaluate and enhance the robustness of Text-to-SQL models against synonym substitutions in natural language questions. Developed by researchers from Queen Mary University of London and collaborators, Spider-Syn is based on the original Spider dataset. |
| SEDE | [Paper][Dateset] | 2021/06, SEDE (Stack Exchange Data Explorer) is new dataset for Text-to-SQL tasks with more than 12,000 SQL queries and their natural language description. It’s based on a real usage of users from the Stack Exchange Data Explorer platform, which brings complexities and challenges never seen before in any other semantic parsing dataset like including complex nesting, dates manipulation, numeric and text manipulation, parameters, and most importantly: under-specification and hidden-assumptions. |
| CHASE | [Paper][Dateset] | 2021/08, CHASE is a large-scale and pragmatic Chinese dataset for cross-database context-dependent text-to-SQL task (natural language interfaces for relational databases). It is released along with our ACL 2021 paper: CHASE: A Large-Scale and Pragmatic Chinese Dataset for Cross-Database Context-Dependent Text-to-SQL. |
| Spider-DK | [Paper][Dateset] | 2021/09, Spider-DK is a benchmark dataset designed to evaluate and enhance the robustness of Text-to-SQL models when handling domain knowledge. Developed by researchers from Queen Mary University of London, Spider-DK builds upon the original Spider dataset |
| EHRSQL | [Paper][Dateset] | 2023/01, EHRSQL is a large-scale, high-quality dataset designed for text-to-SQL question answering on Electronic Health Records from MIMIC-III and eICU. The dataset includes questions collected from 222 hospital staff, such as physicians, nurses, insurance reviewers, and health records teams. |
| BIRD-SQL | [paper][Leaderboard] | 2023/05, the University of Hong Kong and Alibaba propose a large-scale cross-domain dataset BIRD, which contains over 12,751 unique question-SQL pairs, 95 big databases with a total size of 33.4 GB. It also covers more than 37 professional domains, such as blockchain, hockey, healthcare and education, etc. |
| UNITE | [Paper][Dateset] | 2023/05, Unified benchmark is composed of 18 publicly available text-to-SQL datasets, containing natural language questions from more than 12 domains, SQL queries from more than 3.9K patterns, and 29K databases. Compared to the widely used Spider benchmark, we introduce ∼120K additional examples and a threefold increase in SQL patterns, such as comparative and boolean questions. |
| Archer | [Paper] [Leaderboard] | 2024/02, Archer is a challenging bilingual text-to-SQL dataset specific to complex reasoning, including arithmetic, commonsense and hypothetical reasoning. It contains 1,042 English questions and 1,042 Chinese questions, along with 521 unique SQL queries, covering 20 English databases across 20 domains. |
| BookSQL | [Paper][Dateset] | 2024/06, BookSQL has 100k Query-SQL pairs which is about 1.25 times the existing largest Text-2-SQL dataset: WikiSQL. In particular, for designing the queries, we consulted financial experts to understand various practical use cases. We also plan to create a leaderboard where researchers can benchmark various Text-to-SQL models for the accounting domain. |
| Spider 2.0 | [Paper] [Leaderboard] | 2024/08, Spider 2.0, proposed by XLang AI, serves as an advanced evaluation framework for text-to-SQL tasks within real-world enterprise-level workflows. It contains 600 complex text-to-SQL workflow problems, derived from various enterprise database use cases. The dataset includes databases sourced from actual data applications, often containing over 1,000 columns, and stored in cloud or local systems like BigQuery, Snowflake, or PostgreSQL. |
| BEAVER | [Paper[Dateset] | 2024/09, BEAVER, sourced from real enterprise data warehouses together with natural language queries and their correct SQL statements which we collected from actual user history |
| PRACTIQ | [Paper] | 2024/10, PRACTIQ: A Practical Conversational text-to-SQL dataset with Ambiguous and Unanswerable Queries |
| TURSpider | [Paper][Dateset] | 2024/11, TURSpider is a novel Turkish Text-to-SQL dataset that includes complex queries, akin to those in the original Spider dataset. TURSpider dataset comprises two main subsets: a dev set and a training set, aligned with the structure and scale of the popular Spider dataset. The dev set contains 1034 data rows with 1023 unique questions and 584 distinct SQL queries. In the training set, there are 8659 data rows, 8506 unique questions, and corresponding SQL queries. |
| synthetic_text_to_sql | [Dataset] | 2024/11,gretelai/synthetic_text_to_sql is a rich dataset of high quality synthetic Text-to-SQL samples, designed and generated using Gretel Navigator, and released under Apache 2.0. |
SQLFlash is your AI-powered SQL Optimization Partner.
Based on AI models, we accurately identify SQL performance bottlenecks and optimize query performance, freeing you from the cumbersome SQL tuning process so you can fully focus on developing and implementing business logic.
Join us and experience the power of SQLFlash today!.